
Note: Cloud Native
Definizioni e Reference
https://docs.microsoft.com/it-it/dotnet/architecture/cloud-native/definition
Cloud Native Computing Foundation fornisce la definizione ufficiale or https://github.com/cncf/toc/blob/main/DEFINITION.md:
Le tecnologie native del cloud consentono alle organizzazioni di creare ed eseguire applicazioni scalabili in ambienti moderni e dinamici, ad esempio cloud pubblici, privati e ibridi. I contenitori, mesh di servizi, i microservizi, l'infrastruttura e le API esemplificano questo approccio.
URL e Siti web
- https://github.com/cloud-native-go/examples : The official companion repository for Cloud Native Go by Matthew Titmus (O'Reilly Media)
- https://docs.microsoft.com/it-it/dotnet/architecture/cloud-native/introduction : Introduzione alle applicazioni cloud native (estratto da eBook, Progettazione di applicazioni .NET native cloud per Azure, disponibile in .NET Docs)
Componenti principali del Cloud native
- Implementazione delle prassi o del modello DevOps
- Infrastruttura basata su container
- Architettura costruita attorno ai microservizi
- Utilizzo del modello CI/CD (integrazione continua e dell'erogazione continua)

Pets vs Cattle: Animali domestici vs bestiame
Nel modello di servizio pets, ad ogni pet server viene dato un nome affettuoso come zeus, ares, hades, poseidon e athena. Sono "unici, amorevolmente allevati a mano e curati, e quando si ammalano, li curate per farli tornare in salute". Li si potenzia rendendoli più grandi, e quando non sono disponibili, tutti se ne accorgono.
Esempi di pet server includono mainframe, server solitari, bilanciatori di carico e firewall, sistemi di database e così via.
Nel modello di servizio bestiame, ai server vengono dati numeri di identificazione come web01, web02, web03, web04 e web05, allo stesso modo in cui al bestiame vengono dati numeri attaccati all'orecchio. Ogni server è "quasi identico all'altro" e "quando uno si ammala, lo si sostituisce con un altro". Li si scala generandone di più, e quando uno non è disponibile, nessuno se ne accorge.
Esempi di server bestiame includono array di server web, cluster no-sql, cluster di accodamento, cluster di ricerca, cluster di caching reverse proxy, datastore multi-master come Cassandra, soluzioni cluster di big-data, e così via.
Evoluzione del modello Cattle (bestiame)
|
The Iron Age |
Si è avuta l'introduzione della virtualizzazione hardware che ha dato origine ai sistemi di gestione del server. Sono stati sviluppati ed utilizzati gli strumenti di configurazione delle modifiche, che hanno consentito le operazioni di configurazione di gruppi di sistemi in modo automatico. |
|
The First Cloud Age |
Creazione di servizi cloud IaaS (Infrastructure as a Service) che hanno virtualizzato l'intera infrastruttura (reti, storage, memoria, cpu) in risorse programmabili. Piattaforme popolari che offrono IaaS sono Amazon Web Services (2006), Microsoft Azure (2010), Google Cloud Platform (2011). |
|
The Second Cloud Age |
Abbiamo i primi movimenti per virtualizzare o partizionare alcuni aspetti del sistema operativo (processi, rete, memoria, file system). Ciò permette alle applicazioni di essere segregate nel proprio ambiente isolato senza la necessità di dover virtualizzare l'hardware. Alcune di queste tecnologie includono OpenVZ (2005), Linux Containers o LXC (2008), e Docker (2015) |
Nello spazio dei big-data o dello streaming con piattaforme distribuite - Spark, Kafka, Flink, Storm, Hadoop, Cassandra, Samza, Akka, Finagle, Heron, per nominarne solo alcuni -
App cloud native
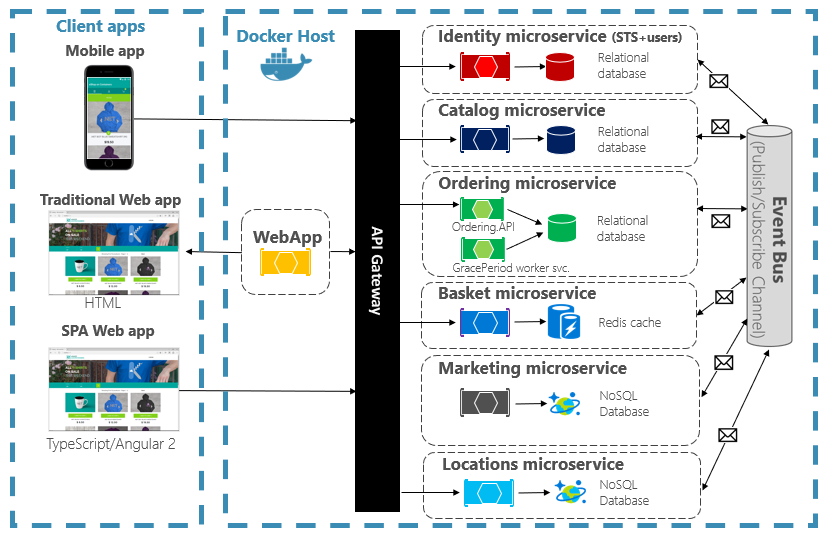
Le architetture Serveless
Un'architettura serverless utilizza servizi esistenti di provider cloud come AWS per implementare i suoi componenti architetturali. Ad esempio, AWS offre servizi per costruire le primitive delle nostre applicazioni, come API (Amazon API Gateway), flussi di lavoro (AWS Step Functions), code (Amazon Simple Queue Service), database (Amazon DynamoDB e Amazon Aurora) e altro ancora.
L'idea di utilizzare servizi esterni per implementare parti della nostra architettura non è nuova, anzi è una best practice fin dai tempi della SOA. Ciò che è cambiato negli ultimi anni è la possibilità di implementare anche gli aspetti personalizzati delle nostre applicazioni (come la logica aziendale) in modo serverless.
Le funzioni e le architetture serverless, in generale, sono versatili. Possono essere utilizzate per creare backend per applicazioni CRUD, e-commerce, sistemi di back-office, applicazioni web complesse e tutti i tipi di software mobile e desktop. I progetti serverless più flessibili e potenti sono event-driven, il che significa che ogni componente dell'architettura reagisce a un cambiamento di stato o a una notifica di qualche tipo, anziché rispondere a una richiesta o eseguire il polling delle informazioni.
Poiché ogni componente è un servizio, le architetture serverless condividono molti vantaggi e complessità con le architetture di microservizi event-driven. Ciò significa anche che le applicazioni devono essere progettate per soddisfare i requisiti di questi approcci (come ad esempio rendere i singoli servizi stateless). L'approccio serverless consiste nel ridurre la quantità di codice da gestire e mantenere, in modo da poter iterare e innovare più velocemente. Per ottenere ciò bisogna cercare di ridurre al minimo il numero di componenti necessari per costruire l'applicazione. I passaggio da un approccio monolitico a un approccio serverless più decentralizzato non riduce automaticamente la complessità del sistema sottostante. Quindi è necessario ridurre al minimo il codice personalizzato, ciò lo si ottiene perchè molti componenti standard delle applicazioni, come API, flussi di lavoro, code e database, sono già disponibili come offerte serverless da parte di provider cloud e terze parti.
GO il linguaggio per il cloud native
 |
||||
 |
 |
|||
- 80 views